S3 Select is a highly valuable and in my option one of the most underappreciated features within AWS S3. As a Data Engineer, it is a must-have in your toolkit.
What is S3 Select?
A feature within S3 that allows you the Data Engineer to run simple SQL queries on objects in S3 buckets. For a more “official” definition I point you to the AWS documentation.
How I use it?
I find S3 Select extremely useful tool for quickly examining files, determining their structure and data types, and identifying any formatting issues. I’ve found it particularly helpful for troubleshooting when clients or processes have generated poorly formatted files.
Using S3 Select with Parquet files has been a huge time-saver, as it eliminates the need to open a notebook and read the file into a dataframe to view it. It is a game-changer for streamlining the data analysis process.
How do you use it?
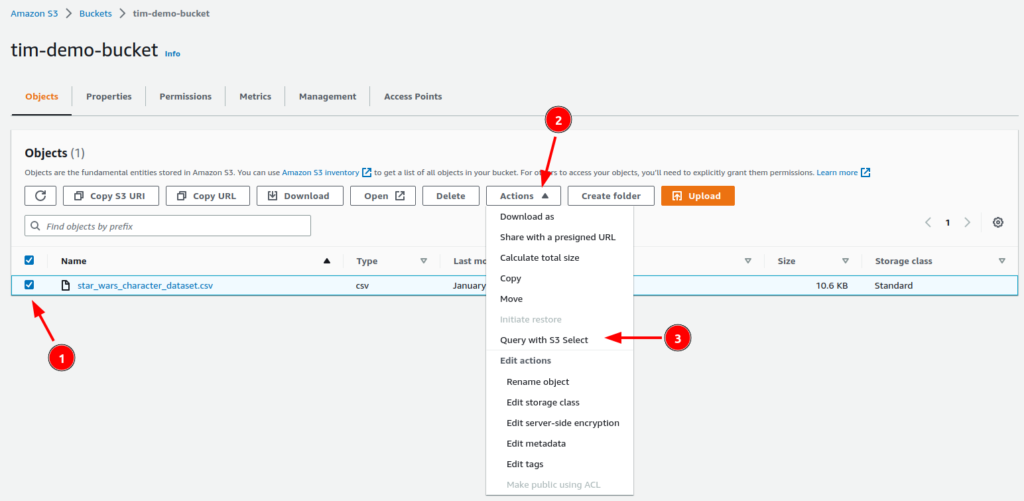
- Within S3 navigate to your chosen bucket and select a file you would like to query the contents of. In this case I am choosing a CSV file called star_wars_character_dataset.csv.
- With the file select click the “Actions” drop down menu.
- Select the option “Query with S3 Select“
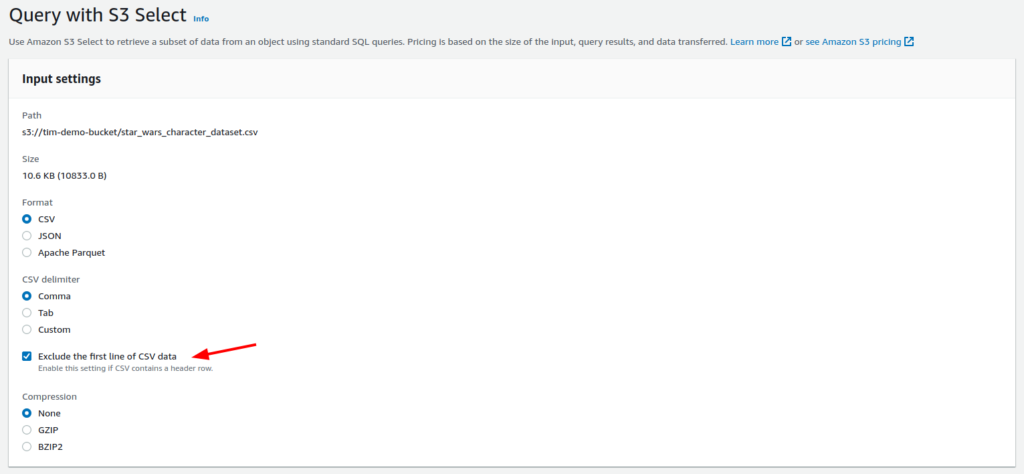
- Select the input setting of your file. S3 does a pretty good at detecting what kind of file it is and setting the options for you. In most cases you can leave the setting as they. Note the tick box to exclude the first line of your file if it contains a header row.
- Scroll down
- Next, select your output settings. S3 hold our hands an selects these settings for us.

- Now the fun part. Type up the SQL query you would like to run on the file (99% of the time your just going to take the default SELECT * FROM s3object s LIMIT 5) and hit “Run SQL query”

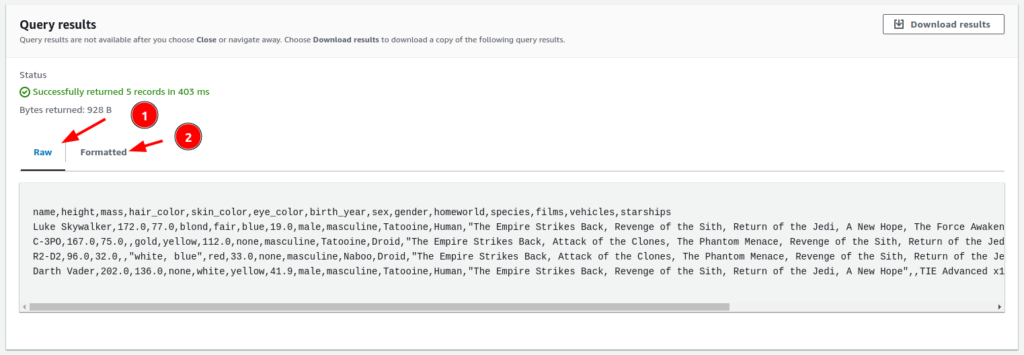
- Your results will be presented back to you where you can then choose to see the results in either raw or formatted version.
Date presented in Raw format
Data Formatted as table
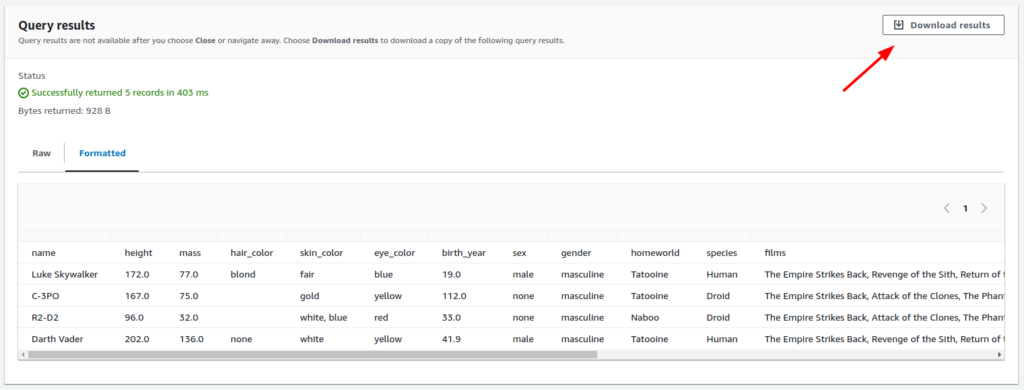
- Finally, Take note that there is a “Download Results” button available for downloading the results in either JSON or CSV format.
Errors when querying
A common error you might run into when querying a CSV file is something like: “The column index at line 1, column 8 is invalid. Please check the service documentation and try again.”

The cause is because you are trying to alter the default SELECT by adding in a column name or a WHERE clause, and your data more than likely contains a header row and S3 has no idea what columns you are talking about because you haven’t set them.
The solution is to make sure you tick “Exclude the first line of CSV data” in the input section of Query with S3 Select
Conclusion
S3 Select enables you to use standard SQL queries to significantly accelerate the process of querying data in S3. I believe it is a must use tool for all Data Engineers.
Tim